이전 포스트에서 eBay Pulsar에 대해서 간단히 알아봤다.
여기서는 Pulsar의 tutorial 및 demo를 통해서 Pulsar에 대해서 좀 더 자세히 알아보도록 한다.
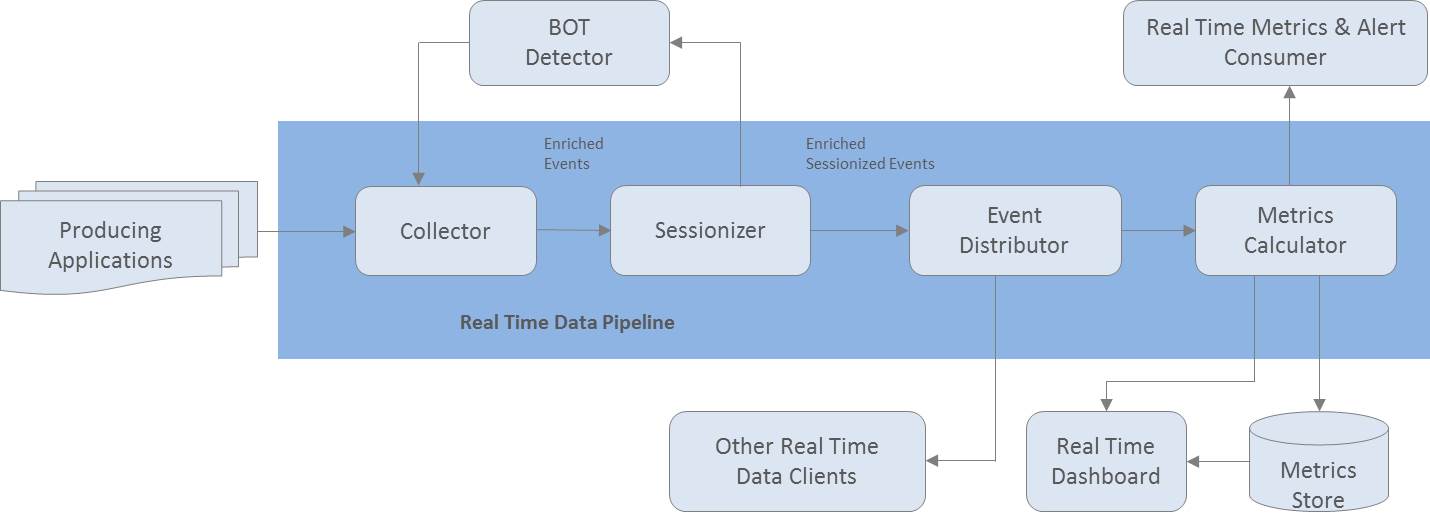
Pulsar의 White Paper를 보면 다음과 같이 간단한 Architecture가 설명되어있다.

<Fig. 1. Real-time Data Pipeline>
Real Time Data Pipeline(이하 Pipeline)은 Collector, Sessionizer, Event Distributor, Metrics Calculator로 구성되어있는 것을 알 수 있다. 각 구성요소에 대해서는 이전 포스트(Pulsar - 오픈소스 실시간 분석 플랫폼 : White Paper)에 간단히 설명되어있다.
Pulsar의 Get Started 페이지에 Demo에 대해서 설명이 되어있다. 설명은 부실할 정보로 매우 간단하게 되어있고 Demo를 실행했을 때의 화면도 보여주고 있다.
이 내용만으로는 직접 데모를 돌려보지 않고 동작을 이해하기는 어려울 것 같다. (데모 페이지의 Pre-Request에는 깨진 링크도 있다!)
데모를 실행하기 위한 Dependency
데모를 실행해보기 위해서는 먼저 Zookeeper, Mongo, Kafka, Cassandra를 설치해야 한다.
Pulsar를 운영하기 위해서 위의 4가지 Dependency가 만족해야 하는 것은 아니다. 이건 어디까지나 Pulsar의 Demo를 실행해보기 위해서 필요한 것이고 모든 구성요소가 Dependency를 필요로 하는 것은 아니다.
아무튼.. Zookeeper, Mongo, Kafka, Cassandra를 설치해야 한다. 다행히 4가지 모두 Pulsar 또는 다른 사람들이 dockerize 해놨기 때문에 귀찮은 설치과정 없이 docker를 통해서 설치 및 실행이 가능하다.
각각에 대해서 알아보면 다음과 같다.
1. Zookeeper
zookeeper는 다음과 같이 실행시키도록 되어있다.
docker run -d --name zkserver -t "jetstream/zookeeper"
jetstream/zookeeper docker image는 기존에 있던 zookeeper image에서 base image를 변경한 것이다. 그리고 expose하는 port는 2181만 정의하고 있다.
2. Mongo
MongoDB는 docker hub에 등록되어있는 일반적인 이미지를 실행시키도록 되어있다.
docker run -d --name mongoserver -t "mongo"
3. Kafka
Kafka는 다음과 같이 jetstream에서 새로 만든 docker image를 사용하도록 되어있다.
docker run -d --name kafkaserver -t "jetstream/kafka"
jetstream/kafka는 zookeeper를 포함하는 kafka single node를 구성한 것이다. jetstream/kafka는 zookeeper에 등록되어있는 broker entry의 advertised ip로 host ip를 사용하도록 되어있다.
4. Cassandra
Cassandra는 docker hub에 등록되어있는 일반적인 이미지를 실행시키도록 되어있다.
docker run -d --name cassandraserver -t "poklet/cassandra"
Cassandra는 metriccalculator에서 집계한 결과를 저장하는 용도로 사용된다. 데이터를 저장하기 위한 테이블은 다음과 같이 생성한다.
mkdir /tmp/pulsarcql
wget https://raw.githubusercontent.com/pulsarIO/realtime-analytics/master/metriccalculator/pulsar.cql -O /tmp/pulsarcql/pulsar.cql
docker run -it --rm --link cassandraserver:cass1 -v /tmp/pulsarcql:/data poklet/cassandra bash -c 'cqlsh $CASS1_PORT_9160_TCP_ADDR -f /data/pulsar.cql'
위에서 설명한 Dependency들은 pipeline의 구성요소들이 사용하게 된다. 하지만 각각의 pipeline 구성요소가 위의 모든 dependency를 필요로 하는 것은 아니다.
각 구성요소별로 어떤 dependency를 필요로 하는가에 대한 것은 Pulsar에서 제공해준 demo 실행 스크립트(https://github.com/pulsarIO/realtime-analytics/blob/master/Demo/rundemo.sh)를 보면 알 수 있다.
Pipeline의 구성요소
demo 실행 스크립트를 확인해보면 다음과 같은 순서대로 pipeline 구성요소를 실행시킨다.
1. config
docker run -d -p 0.0.0.0:8000:9999 -p 0.0.0.0:8081:8080 --link zkserver:zkserver --link mongoserver:mongoserver -t "jetstream/config"
--link로 설정된 부분을 보면 config는 Zookeeper, MongoDB를 사용하는 것을 알 수 있다.
그런데 config(ConfigApp)는 위에서 보여준 Architecture에 포함되어있지 않다. config의 역할은 전체 pipeline의 provision configuration을 관리하는 것이다.
config에서 연결하는 시스템을 봤을 때 pipeline의 configuration을 저장하는 용도로 사용되는 것을 알 수 있다.
config는 Jetstream에 포함되어있는 구성요소이다.
2. replay
Replay에 대해서는 Pulsar의 Get Started 페이지에서 다음과 같이 설명하고 있다.
Replay는 Queue Full, 네트워크 부하 등으로 다른 stage에서 처리 실패한 이벤트를 replay시키는 역할을 한다.
너무 의역한 것이기는 하지만 아무튼 이런 역할을 한다. -_-
replay는 이벤트에 tag를 달아서 해당 이벤트가 replay에 의해서 보내진 것인지를 알 수 있도록 한다.
demo 실행 스크립트에서는 replay를 다음과 같이 실행시킨다.
docker run -d -p 0.0.0.0:8001:9999 --link zkserver:zkserver --link mongoserver:mongoserver --link kafkaserver:kafkaserver -t "pulsar/replay"
replay는 kafka, mongodb, zookeeper에 대한 의존성을 가지고 있다.
3. Sessionizer
Sessionizer는 이벤트의 session state를 관리하고 session marker event를 생성하는 역할을 한다. Pulsar 홈페이지에서는 Sessionizer는 si를 affinity key로 사용하여 동일한 si event는 동일한 노드로 라우팅된다고 설명하고 있다. 그런데 si가 어떤 것을 의미하는지에 대해서는 설명이 되어있지 않다. 그냥 Session Identifier 정도로 예상하고 있다.
session state라는 것은 session의 메타데이터(자주 변하지 않는 ip, user agent정보 등)와 variables를 포함한다. sessionizer의 로직은 EPL에 의해저 정의되어있다.
demo 실행 스크립트에서는 다음과 같이 실행시키고 있다.
docker run -d -p 0.0.0.0:8003:9999 --link zkserver:zkserver --link mongoserver:mongoserver --link kafkaserver:kafkaserver -t "pulsar/sessionizer"
replay와 마찬가지로 cassandra를 제외한 나머지 3개 시스템(kafka, mongodb, zookeeper)에 대한 의존성을 가지고 있다.
4. Distributor
Distributor는 이벤트를 각 목적지에 맞게 전달해주거나 걸러내거나 변형시키는 역할을 한다. 사용자는 EPL을 통해서 설정하는 것이 가능하다.
demo 실행 스크립트에서의 실행은 다음과 같다.
docker run -d -p 0.0.0.0:8004:9999 --link zkserver:zkserver --link mongoserver:mongoserver --link kafkaserver:kafkaserver -t "pulsar/distributor"
5. Metrics Calculator
이름 그대로 metric을 계산해서 저장하는 역할을 한다.
demo 실행 스크립트에서의 실행은 다음과 같다.
docker run -d -p 0.0.0.0:8005:9999 --name metriccalculator --link zkserver:zkserver --link mongoserver:mongoserver --link kafkaserver:kafkaserver --link cassandraserver:cassandraserver -t "pulsar/metriccalculator"
다른 구성요소와는 달리 cassandra와 연결을 가지고 있는 것을 볼 수 있다.
Metrics Calculator는 2개의 stage로 구성되어있다. 첫번째 stage는 짧은 시간동안의 집계를 수행하고 그 후에 두번째 stage를 통해서 긴 시간동안의 집계를 수행하게 된다.
6. Collector
pipeline의 구성요소 중 가장 앞에 들어가는 요소인데 demo 실행 스크립트에서는 제일 마지막에 실행시킨다.
실행은 다음과 같이 되어있다.
docker run -d -p 0.0.0.0:8002:9999 -p 0.0.0.0:8080:8080 --link zkserver:zkserver --link mongoserver:mongoserver --link kafkaserver:kafkaserver -t "pulsar/collector"
이름 그대로 event를 수집하는 역할을 한다.
Demo의 실행
Pulsar 홈페이지에서는 다음의 3가지 Demo Applications를 제공해주고 있다.
1. MetricService : MetricUI를 위한 metric을 제공해주는 역할을 한다.
2. MetricUI : Metric Dashboard
3. TwitterSample : 트위터에서 발생하는 이벤트를 pulsar로 넣어주는 샘플
Pulsar의 demo 실행 스크립트에서는 MetricService, MetricUI순으로 실행한 후 제일 마지막에 TwitterSample을 실행시키도록 되어있다.
특징으로 보면.. TwitterSample은 데이터를 입력하는 역할을 하고 MetricService, MetricUI는 pipeline을 지나온 결과를 출력하는 역할을 한다.
그런데 TwitterSample의 코드에서 wiring관련 xml을 보면 다음과 같은 내용이 있다.
<bean id="OutboundMessageChannelAddress"
class="com.ebay.jetstream.event.channel.messaging.MessagingChannelAddress">
<property name="channelTopics">
<list>
<value>Pulsar.MC/ssnzEvent</value>
</list>
</property>
</bean>
TwitterSample을 데이터를 만들어낸 후 Pulsar.MC/ssnzEvent로 보내는 것을 확인할 수 있다.
Pulsar의 Architecture 그림을 보면 처음 들어온 이벤트는 Collector에 의해서 수집된 후 Sessionizer로 전달되어야 하는데 Collector의 inbound 설정을 보면 다음과 같이 되어있다.
<bean id="InboundChannelAddress"
class="com.ebay.jetstream.event.channel.messaging.MessagingChannelAddress">
<property name="channelTopics">
<list>
<value>Pulsar.collector/rawEvent</value>
</list>
</property>
</bean>
위의 내용을 종합해보면 TwitterSample은 Collector로 이벤트를 전달하지 않도록 되어있다. Pulsar.MC/ssnzEvent를 통해서 전달받는 구성요소는 MetricCalculator이다.
Pulsar의 TwitterSample은 자신들이 그려놓은 Architecture와는 맞지 않게 Collector가 아닌 MetricCalculator로 이벤트를 전달하는 것을 알 수 있다.
왜 이런 사태가 발생했는지 간단히 알아보도록 하자.
Pulsar의 정체
Pulsar의 wiki에 보면 Pulsar에 대해서 설명하고 있다. 하지만 천천히 잘 읽어봐도 도대체 Pulsar가 뭔지에 대한 실체를 알기 힘들다. wiki의 Overview에서 설명하는 Pulsar의 특징은 다음과 같다.
1. Pulsar는 Open source realtime analytics platform이다.
2. 사용자가 발생시키는 event(user behavior event)를 실시간으로 수집하고 처리한다.
3. realtime sessionization, multi-dimensional metrics aggregation을 제공한다.
4. SQL-like한 언어를 써서 데이터를 가공하거나 걸러낼 수 있다.
5. 고가용성의 특징을 가지면서 초당 수백만의 이벤트까지 처리할 수 있도록 확장 가능하다.
6. Cassandra나 Druid와 같은 metrics stores와 쉽게 integration이 된다.
위의 특징을 봤을 때 가장 먼저 떠오르는 질문은 다음과 같다.
"user behavior event가 아닌 다른 event를 처리하는 것이 가능한가?"
Collector의 소스를 보면 답을 얻을 수 있다.
Collector에서 연결 관계를 설명하고 있는 appwiring.xml파일을 보면 다음과 같은 내용이 있다.
....생략....
<bean id="InboundChannelAddress"
class="com.ebay.jetstream.event.channel.messaging.MessagingChannelAddress">
<property name="channelTopics">
<list>
<value>Pulsar.collector/rawEvent</value>
</list>
</property>
</bean>
....생략....
<bean id="InboundMessages"
class="com.ebay.jetstream.event.channel.messaging.InboundMessagingChannel">
<property name="address" ref="InboundChannelAddress" />
<property name="waitTimeBeforeShutdown" value="5000"/>
<property name="eventSinks">
<list>
<ref bean="EsperProcessor" />
</list>
</property>
</bean>
<bean id="EsperProcessor" class="com.ebay.jetstream.event.processor.esper.EsperProcessor">
<property name="esperEventListener" ref="EsperEventListener" />
<property name="configuration" ref="EsperConfiguration" />
<property name="epl" ref="EPL" />
<property name="eventSinks">
<list>
<ref bean="OutboundMessages" />
</list>
</property>
<property name="adviceListener" ref="CollectorRawEventAdviceProcessor"/>
</bean>
Pulsar.collector/rawEvent로부터 받은 이벤트를 EPL을 통해서 처리한 후 outBound로 보내는 것을 알 수 있다.
EPL에 대해서는 EPL.xml에 다음과 같이 정의되어있다.
<bean id="EPL" class="com.ebay.jetstream.event.processor.esper.EPL">
<property name="statementBlock">
<value>
<![CDATA[
update istream PulsarRawEvent set ct = System.currentTimeMillis()
where ct is null;
insert into PulsarEvent
select
DeviceEnrichmentUtil.getDeviceInfo(ua) as device,
GeoEnrichmentUtil.getGeoInfo(ipv4) as geo,
raw as originEvent
from PulsarRawEvent as raw;
@ClusterAffinityTag(colname="si")
@OutputTo("OutboundMessages")
select device.userAgentVersion as _dd_bv,
device.userAgentFamily as _dd_bf,
device.userAgentType as _dd_d,
device.deviceCategory as _dd_dc,
device.osFamily as _dd_os,
device.osVersion as _dd_osv,
geo.city as _cty,
geo.continent as _con,
geo.country as _cn,
geo.region as _rgn,
geo.longitude as _lon,
geo.latitude as _lat,
geo.countryIsoCode as _tlcn,
originEvent.* from PulsarEvent;
]]>
</value>
</property>
</bean>
위의 EPL에서 기술하고 있는 ct라든지 ua, ipv4는 어디에서 온 것인지 궁금할 수 있다. Collector의 Simulator의 소스를 보면 Event.txt에서 이벤트의 형태를 가지고 있다는 것을 알 수 있다.
Event.txt는 다음과 같다.
{
"si": "${siValue}",
"ac": "727354723",
"tn": "TenantName",
"or": "OrignalName",
"ct": ${ctValue},
"ipv4": "${ipValue}",
"ua": "${uaValue}",
"et": "Mobile",
"rf": "http://referrer.somewhere.com",
"url": "http://LandingPage.com",
"itmT":"${itmTitle}",
"itmP":${itmPrice},
"cap":"${campaignName}",
"capG":${cmapaignGMV},
"capQ":${cmapaignQuantity}
}
Pulsar의 Collector에서 처리하고 있는 이벤트의 모습을 보면 Pulsar의 Overview를 읽고 생긴 질문에 답을 할 수 있게 된다.
"user behavior event가 아닌 다른 event를 처리하는 것이 가능한가?"
=> 넹~ 하지만 쉽지는 않아요..
다른 이벤트에 대해서 Collector의 xml을 수정해서 처리해야 하는 이벤트에 맞게 바꿔줘야 하고 EPL도 그것에 맞도록 수정해야 한다.
아무튼.. xml을 보고 수정할 수 있고 EPL을 쓸 수 있다면 그럭저럭 Pulsar를 사용해서 이벤트 처리를 할 수 있다.
Pulsar의 Wiki에서는 Pulsar의 각 Stage(Pipeline의 구성요소)는 모두 Distributed CEP Framework를 사용해서 만들었다고 소개하고 있다. Distributed CEP Framework의 이름은 Jetstream이다.
Collector, Sessionizer, Distributor의 코드를 보면 매우 단순하게 되어있다. 모두 Jetstream을 기반으로 했기 때문에 Stage간의 데이터 전달, Esper Integration 등을 신경쓸 필요가 없기 때문이다.
심지어는 TwitterSample도 Jetstream기반으로 만들어져있다!
아무튼.. Pulsar는 Jetstream을 기반으로 한 사용자 행동에 관련한 이벤트를 처리하는 Platform이라고 생각하면 된다.
그렇기 때문에 TwitterSample은 Jetstream 기반의 Component간의 데이터 처리에 대해서 보여준 것이지 Pulsar에 대한 Demo는 아니다.
Pulsar는 Collector, Sessionizer등으로 구성된 Pipeline을 활용하여 실시간 처리를 빠르게 할 수 있다는 장점 말고도 Pulsar를 구현한 Jetstream을 이용하여 상황에 맞는 Pipeline을 쉽게 구축할 수 있다는 장점을 가지고 있다.