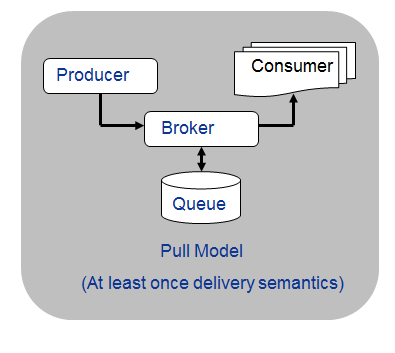
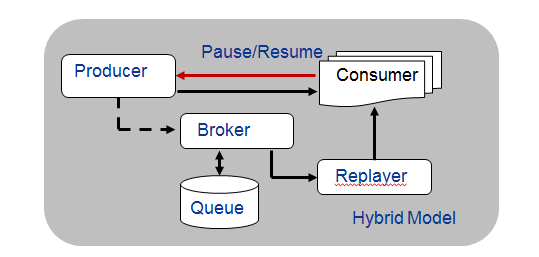
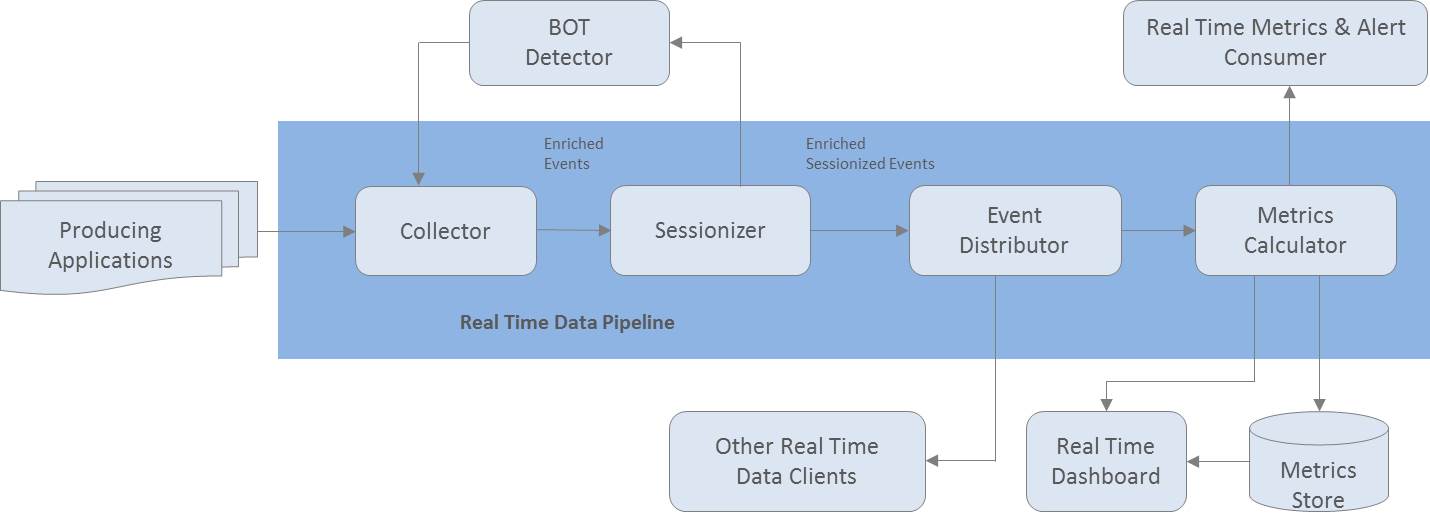
eBay Pulsar를 분석하면서 받은 느낌은 다음과 같다.
"eBay Pulsar를 바로 써먹는 것은 불가능해보인다. Jetstream을 이용하면 CEP 시스템을 쉽게 구축할 수 있을 것 같고 eBay Pulsar는 Jetstream을 활용하기 위해서 참고하는 소스 정도로 사용하면 될 것 같다."
문제는 Jetstream의 문서를 봐도 이해가 잘 되도록 되어있지는 않다는 것이다.
Jetstream을 이용해서 간단한 Pipeline을 구성하면서 Jetstream에 대해서 이해할 수 있도록 하자.
Jetstream App 만들기
maven이 설치되어있다면 다음과 같은 명령으로 Jetstream App을 만들 수 있다.
mvn archetype:generate -DarchetypeGroupId=com.ebay.jetstream.archetype -DarchetypeArtifactId=simpleapp -DarchetypeVersion=4.0.2
위의 명령을 실행시키면 groupId, artifactId 등을 물어본다. 적당히 입력하면 Jetstream Sample App이 만들어진다.
$ mvn archetype:generate -DarchetypeGroupId=com.ebay.jetstream.archetype -DarchetypeArtifactId=simpleapp -DarchetypeVersion=4.0.2
....
Define value for property 'groupId': : com.embian.test
Define value for property 'artifactId': : pulsar-test
Define value for property 'version': 1.0-SNAPSHOT:
Define value for property 'package': com.embian.test:
Confirm properties configuration:
groupId: com.embian.test
artifactId: pulsar-test
version: 1.0-SNAPSHOT
package: com.embian.test
...
mvn을 돌린 위치에 artifactId로 입력했던 pulsar-test라는 디렉토리가 생성된 것을 확인할 수 있다.
pulsar-test는 자신이 사용하는 IDE에 맞게 설정해서 Import하면 된다.
XML파일 이해하기
Jetstream에서 사용하는 주요한 XML은 다음과 같다.
buildsrc/JetstreamConf/appwiring.xml
InboundChannel과 OutboundChannel에 대한 정의를 가지고 있다.
기본으로 생성된 App의 설정파일은 다음과 같다. XML을 한번에 보면 머리아프기 때문에 역할별로 떼어서 보도록 하겠다.
XML의 제일 상단 부분에 위치한 내용이다. 따로 설명이 필요 없으니 Pass.
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans-4.0.xsd"
default-lazy-init="false">
그 후에 나오는 부분은 다음과 같다.
<bean id="InboundMessageBinder"
class="com.ebay.jetstream.event.support.channel.ChannelBinding"
depends-on="MessageService">
<property name="channel" ref="InboundMessages"/>
</bean>
<bean id="InboundMessages"
class="com.ebay.jetstream.event.channel.messaging.InboundMessagingChannel">
<property name="address" ref="InboundChannelAddress" />
<property name="waitTimeBeforeShutdown" value="15000"/>
<property name="eventSinks">
<list>
<ref bean="SampleProcessor" />
</list>
</property>
</bean>
<bean id="InboundChannelAddress"
class="com.ebay.jetstream.event.channel.messaging.MessagingChannelAddress">
<property name="channelTopics">
<list>
<value>Jetstream.sample/SampleEvent</value>
</list>
</property>
</bean>
<bean id="SampleProcessor" class="com.embian.test.processor.SampleProcessor">
<property name="eventSinks">
<list>
<ref bean="OutboundMessages" />
</list>
</property>
</bean>
Inbound에 대한 설정이다.
InboundMessageBinder(첫번째 Bean)에서는 Message 전송 방식을 어떤식으로 쓸 것인지를 정의한다. depends-on="MessageService" 부분이 이 부분이다. MessageService에 대해서는 appwiring.xml에 나와있지 않다. 해당 정보는 나중에 볼 messagecontext.xml에서 확인할 수 있다.
아무튼.. MessageService라는 방식으로 Message를 전송하면서 Channel은 InboundMessages라는 Bean을 사용한다는 것이다.
두번째 Bean인 InboundMessages를 보면 InboundChannelAddress에 주소가 정의되어있고 eventSinks로 SampleProcessor를 추가한 것을 확인할 수 있다.
그 밑에는 각각 InboundChannelAddress와 SampleProcessor에 대해서 정의되어있다.
InboundChannelAddress는 topic으로 Jetstream.sample/SampleEvent를 가지는 채널을 의미하고 SampleProcessor는 com.embian.test.processor.SampleProcessor 클래스를 나타내고 있다.
종합해서 보면 Inbound는 Jetstream.sample/SampleEvent라는 토픽을 가지고 있는 통로를 통해서 메시지를 받아오고 받아온 메시지는 SampleProcessor에서 처리한다는 것이다.
SampleProcessor부분에 보면 eventSinks로 OutboundMessages가 정의되어있다. SampleProcessor에서 처리를 끝낸 것은 OutboundMessages를 통해서 전달된다는 것을 의미한다.
여기까지의 내용을 그림으로 표시하면 다음과 같다.

<그림 1. pulsar-test의 Inbound 설정 내용>
Inbound에 대한 설정 바로 밑에는 Outbound에 대한 설정이 있다.
<bean id="OutboundMessageChanneBinder" class="com.ebay.jetstream.event.support.channel.ChannelBinding"
depends-on="MessageService">
<property name="channel" ref="OutboundMessages" />
</bean>
<bean id="OutboundMessages"
class="com.ebay.jetstream.event.channel.messaging.OutboundMessagingChannel"
depends-on="MessageService">
<property name="address" ref="OutboundMessageChannelAddress" />
</bean>
<bean id="OutboundMessageChannelAddress"
class="com.ebay.jetstream.event.channel.messaging.MessagingChannelAddress">
<property name="channelTopics">
<list>
<value>Jetstream.sample2/SampleEvent</value>
</list>
</property>
</bean>
OutboundMessageChannelBinder에서 OutboundMessages를 채널로 정의하고 있고 OutboundMessages의 주소는 OutboundMessageChannelAddress에서 정의하고 있다. OutbountMessageChannelBinder와 OutboundMessages에 대한 정의는 MessageService를 참고하고 있다는 것을 알 수 있다.
요약하자면.. OutboundMessage는 Jetstream.sample2/SampleEvent를 토픽으로 가지고 있는 통로를 사용한다는 것이다.
Outbound까지의 내용을 <그림 1>에 추가하면 다음과 같다.

여기까지 해서 Pipeline 구성에 대한 가장 기본적인 wiring이 끝난 것이다.
outbound에 대한 설정 밑에는 Shutdown에 대한 설정이 들어가있다.
<bean id="ShutDownOrchestrator" class="com.ebay.jetstream.event.support.ShutDownOrchestrator"
lazy-init="false">
<property name="shutDownComponent">
<list>
<ref bean="InboundMessages" />
<ref bean="SampleProcessor" />
<ref bean="OutboundMessages" />
</list>
</property>
</bean>
오류가 발생한 경우 Shutdown을 시키는 processor에 대해서 정의한 것이다.
Shutdown이 발생하면 채널과 processor를 닫는 방법에 대해서 추가할 수 있도록 한 것이다.
그리고 appwiring.xml은 이해하기 쉽게 이름을 변경하는 것도 가능하다.
buildsrc/JetstreamConf/messagecontext.xml
appwiring.xml은 Processor와 Channel간의 연결에 대해서 설정하는 반면에 messagecontext.xml은 실제 메시지 전달을 위해서 어떤 방식으로 전달할 것인가를 나타내는 설정이다.
appwiring.xml에서 언급했던 MessageService에 대해서 찾아보면 다음과 같이 되어있다.
<bean id="MessageService"
class="com.ebay.jetstream.messaging.config.MessageServiceConfiguration"
depends-on="SystemPropertiesConfiguration">
<property name="messageServiceProperties" ref="MessageServiceProperties" />
</bean>
MessageServiceProperties를 확인해보면 Jetstream.sample과 Jetstream.sample2에 대해서 정의되어있는 것을 확인할 수 있다.
<bean id="MessageServiceProperties"
class="com.ebay.jetstream.messaging.config.MessageServiceProperties">
<property name="nicUsage" ref="NICUsage" />
<property name="transports">
<list>
<ref bean="zookeeper" />
<bean
class="com.ebay.jetstream.messaging.transport.netty.config.NettyTransportConfig">
<property name="transportClass"
value="com.ebay.jetstream.messaging.transport.netty.NettyTransport" />
<property name="transportName" value="netty" />
<property name="protocol" value="tcp" />
<property name="contextList">
<list>
<bean
class="com.ebay.jetstream.messaging.transport.netty.config.NettyContextConfig">
<!-- TODO: Change to your context name -->
<property name="contextname" value="Jetstream.sample" />
<property name="port" value="15590" />
<property name="scheduler" ref="consistenthashingaffinityscheduler"/>
</bean>
</list>
</property>
<property name="sendbuffersize" value="1048576" />
<property name="receivebuffersize" value="1048576" />
<property name="downstreamDispatchQueueSize" value="262144" />
<property name="connectionTimeoutInSecs" value="10" />
<property name="asyncConnect" value="true" />
<property name="numAcceptorIoProcessors" value="1" />
<property name="numConnectorIoProcessors" value="1" />
<property name="requireDNS" value="false" />
<property name="netmask" value="#{systemProperties['jetstream.runtime.netmask'] ?: '127.0.0.1/8'}" />
<property name="connectionPoolSz" value="1" />
<property name="maxNettyBackLog" value="20000" />
<property name="idleTimeoutInSecs" value="8640000"/>
<property name="enableCompression" value="false" />
<property name="tcpKeepAlive" value="true"/>
</bean>
<bean
class="com.ebay.jetstream.messaging.transport.netty.config.NettyTransportConfig">
<property name="transportClass"
value="com.ebay.jetstream.messaging.transport.netty.NettyTransport" />
<property name="transportName" value="netty" />
<property name="protocol" value="tcp" />
<property name="contextList">
<list>
<bean
class="com.ebay.jetstream.messaging.transport.netty.config.NettyContextConfig">
<!-- TODO: Change to your context name -->
<property name="contextname" value="Jetstream.sample2" />
<property name="port" value="15591" />
<property name="scheduler" ref="consistenthashingaffinityscheduler"/>
</bean>
</list>
</property>
<property name="sendbuffersize" value="1048576" />
<property name="receivebuffersize" value="1048576" />
<property name="downstreamDispatchQueueSize" value="262144" />
<property name="connectionTimeoutInSecs" value="10" />
<property name="asyncConnect" value="true" />
<property name="numAcceptorIoProcessors" value="1" />
<property name="numConnectorIoProcessors" value="1" />
<property name="requireDNS" value="false" />
<property name="netmask" value="#{systemProperties['jetstream.runtime.netmask'] ?: '127.0.0.1/8'}" />
<property name="connectionPoolSz" value="1" />
<property name="maxNettyBackLog" value="20000" />
<property name="idleTimeoutInSecs" value="8640000"/>
<property name="enableCompression" value="false" />
<property name="tcpKeepAlive" value="true"/>
</bean>
</list>
</property>
<property name="upstreamDispatchQueueSize" value="300000" />
<property name="upstreamDispatchThreadPoolSize" value="2" />
</bean>
Jetstream.sample은 15590 포트를, Jetstream.sample2는 15591 포트를 통해서 통신하도록 정의되어있다.
Processor 만들기
XML 파일을 통해서 Inbound와 Outbound에 대한 연결 설정이 끝나면 해당 App이 Inbound를 통해서 들어온 Message를 어떻게 처리한 후 Outbound로 보낼지에 대해서 구성해야 한다.
Inbound의 설정 중 eventSinks에서 정의한 Processor Class에서 Data의 처리를 수행하게 된다. 아래의 XML은 appwiring.xml에서 Processor에 대한 정의 부분이다. 이미 앞에서 알아봤던 XML에 기록되어있는 것을 다시한번 확인해보면 다음과 같다.
<bean id="InboundMessages"
class="com.ebay.jetstream.event.channel.messaging.InboundMessagingChannel">
<property name="address" ref="InboundChannelAddress" />
<property name="waitTimeBeforeShutdown" value="15000"/>
<property name="eventSinks">
<list>
<ref bean="SampleProcessor" />
</list>
</property>
</bean>
<bean id="SampleProcessor" class="com.embian.test.processor.SampleProcessor">
<property name="eventSinks">
<list>
<ref bean="OutboundMessages" />
</list>
</property>
</bean>
위의 XML에서는 Inbound로 들어오는 Message를 SampleProcessor로 전달한다는 것을 의미한다. 그리고 SampleProcessor는 결과를 OutboundMessages로 보내도록 정의되어있다.
SampleProcessor는 com.embian.test.processor.SampleProcessor라는 Custom Processor를 의미한다. Processor에 EsperProcessor를 붙여서 바로 EPL처리를 하는 것도 가능하다. 먼저 Custom Processor에 대해서 알아본 후 EsperProcessor에 대해서 알아보도록 하겠다.
- CustomProcessor
CustomProcessor는 Jetstream의 AbstractEventProcessor를 상속받아서 구현할 수 있다. SampleProcessor의 내용을 보면 다음과 같다.
package com.embian.test.processor;
import org.springframework.context.ApplicationEvent;
import org.springframework.jmx.export.annotation.ManagedResource;
import com.ebay.jetstream.event.EventException;
import com.ebay.jetstream.event.JetstreamEvent;
import com.ebay.jetstream.event.support.AbstractEventProcessor;
import com.ebay.jetstream.management.Management;
@ManagedResource(objectName = "Event/Processor", description = "SampleProcessor")
public class SampleProcessor extends AbstractEventProcessor {
private JetstreamEvent lastEvent;
@Override
public void afterPropertiesSet() throws Exception {
Management.addBean(getBeanName(), this);
}
public JetstreamEvent getLastEvent() {
return lastEvent;
}
@Override
public int getPendingEvents() {
return 0;
}
@Override
public void pause() {
}
@Override
protected void processApplicationEvent(ApplicationEvent event) {
}
@Override
public void resume() {
}
@Override
public void sendEvent(JetstreamEvent event) throws EventException {
lastEvent = event;
super.incrementEventRecievedCounter();
super.fireSendEvent(event);
super.incrementEventSentCounter();
}
public void setLastEvent(JetstreamEvent lastEvent) {
this.lastEvent = lastEvent;
}
@Override
public void shutDown() {
}
}
위의 코드는 Jetstream App을 만들면 기본적으로 생성되는 코드이다. 각 method들이 유용하게 사용될 수 있지만 여기서는 가장 기본적인 method에 대해서만 알아보도록 하겠다.
afterPropertiesSet method
afterPropertiesSet method는 이름 그대로 Processor가 properties를 설정한 직후 호출되는 method이다. 초기에 설정 등이 필요한 부분은 여기에서 처리하면 된다.
sendEvent method
sendEvent method는 XML에서 정의된 eventSinks로 message를 보낼 때 사용된다. 코드 내에서 fireSendEvent method를 사용하는 것을 볼 수 있다. 이 method가 eventSinks로 message를 보내는 역할을 한다. 만약 Pulsar의 예제처럼 IP를 통해서 국가 코드를 얻고자 하는 경우 fireSendEvent를 하기 전에 필요한 정보를 추가하면 된다.
event에서 정보를 읽거나 쓸때는 event.put, event.get method를 사용할 수 있다.
- EsperProcessor
만약 위의 예제에서 SampleProcessor를 CustomProcessor가 아닌 EsperProcessor를 사용하도록 하기 위해서는 appwiring.xml을 다음과 같이 수정하면 된다.
<bean id="SampleProcessor"
class="com.ebay.jetstream.event.processor.esper.EsperProcessor">
<property name="esperEventListener" ref="EsperEventListener" />
<property name="configuration" ref="EsperConfiguration" />
<property name="epl" ref="EPL" />
<property name="eventSinks">
<list>
<ref bean="OutboundMessages" />
</list>
</property>
<property name="esperExceptionHandler">
<bean id="esperExceptionHandler"
class="com.ebay.jetstream.event.processor.esper.EsperExceptionHandler"></bean>
</property>
</bean>
property 중 esperEventListener와 configuration, epl은 bean으로 등록되어있어야 한다.
이 bean들을 등록하기 위한 XML은 다음과 같다.
EsperSetup.xml
<?xml version="1.0" encoding="UTF-8"?>
<!--
Pulsar
Copyright (C) 2013-2015 eBay Software Foundation
Licensed under the GPL v2 license. See LICENSE for full terms.
-->
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:util="http://www.springframework.org/schema/util"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans-4.0.xsd"
default-lazy-init="true">
<bean id="EsperEventListener"
class="com.ebay.jetstream.event.processor.esper.EsperEventListener">
</bean>
<bean id="EsperConfiguration"
class="com.ebay.jetstream.event.processor.esper.EsperConfiguration">
<property name="internalTimerEnabled" value="true" />
<property name="msecResolution" value="1" />
<property name="timeSourceNano" value="false" />
<property name="declaredEvents" ref="EventDefinition" />
<property name="listenerDispatchTimeout" value="1000" />
<property name="listenerDispatchPreserveOrder" value="false" />
<property name="insertIntoDispatchTimeout" value="100" />
<property name="insertIntoDispatchPreserveOrder" value="false" />
<property name="threadPoolSize" value="2" />
<property name="queueSizeLimit" value="30000" />
<property name="executionLogging" value="true" />
<property name="timerLogging" value="true" />
<property name="exceptionHandlerFactoryClass"
value="com.ebay.jetstream.event.processor.esper.JetstreamExceptionHandlerFactory" />
<property name="autoImport">
<list>
</list>
</property>
</bean>
<bean id="EventDefinition"
class="com.ebay.jetstream.event.processor.esper.EsperDeclaredEvents">
<property name="eventTypes">
<list>
<bean
class="com.ebay.jetstream.event.processor.esper.MapEventType">
<property name="eventAlias" value="SampleEvent" />
<property name="eventFields">
<map>
<entry key="data" value="java.lang.String" />
</map>
</property>
</bean>
</list>
</property>
</bean>
</beans>
EsperEventListener는 Jetstream의 Esper Listener 설정을 나타내고 EsperConfiguration은 기본적인 Esper 설정을 나타낸다. EsperSetup.xml에서 관심있게 봐야 하는 부분은 EventDefinition이라는 bean이다.
EPL을 사용하기 위해서 Event Type을 정의하는 부분이다. eventTypes라는 property에는 EPL에서 사용할 Event의 Type이 정의된다. 여기서는 string값을 갖는 data라는 이름의 항목만 있는 SampleEvent라는 이벤트를 정의했다.
EPL.xml
<?xml version="1.0" encoding="UTF-8"?>
<!--
Pulsar
Copyright (C) 2013-2015 eBay Software Foundation
Licensed under the GPL v2 license. See LICENSE for full terms.
-->
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans-4.0.xsd"
default-lazy-init="true">
<bean id="EPL" class="com.ebay.jetstream.event.processor.esper.EPL">
<property name="statementBlock">
<value>
<![CDATA[
@OutputTo("OutboundMessages")
select data, count(*) as cnt from SampleEvent.win:time(10) group by data;
]]>
</value>
</property>
</bean>
</beans>
EPL은 위와 같이 설정된다. @OutputTo라는 Annotation을 통해서 해당 EPL의 결과를 eventSinks에서 정의된 목록 중 어디로 보낼지를 결정할 수 있다. 위의 예제는 10초동안 data가 종류별로 몇개가 들어왔는지를 세어보는 EPL이다.
이와 같이 설정되어있을 경우.. Inbound를 통해서 들어온 이벤트는 다음과 같이 정의가 되어있다는 것을 알 수 있다.
이 이벤트가 EPL을 통해서 OutboundMessage로 전달될 때는 다음과 같은 형태가 된다.
{
"data": 문자열1,
"cnt": 문자열개수
}
결과 이벤트는 위의 내용 말고도 어떤 이벤트 타입인지가 js_ev_type이라는 이름 등을 통해서 추가된다.
Custom Channel 만들기
이벤트가 생성되는 시점이나 이벤트를 저장소 등에 저장하고 싶을 때 Custom Channel을 통해서 처리할 수 있다. Jetstream에서는 AbstractInboundChannel을 상속받아서 Custom Channel을 만드는 것이 가능하다.
여기서는 0.5초마다 단어를 선택해서 outbound로 던지는 예제를 보면서 Custom Channel을 만들어보도록 하겠다.
package com.embian.channel;
import java.util.Timer;
import java.util.TimerTask;
import org.springframework.context.ApplicationEvent;
import org.springframework.jmx.export.annotation.ManagedOperation;
import com.ebay.jetstream.event.EventException;
import com.ebay.jetstream.event.JetstreamEvent;
import com.ebay.jetstream.event.channel.AbstractInboundChannel;
import com.ebay.jetstream.event.channel.ChannelAddress;
import com.ebay.jetstream.management.Management;
public class WordCountChannel extends AbstractInboundChannel {
private Timer timer = new Timer("Timer");
private TimerTask timerTask;
private Boolean channelOpened;
private class TimingTask extends TimerTask {
public void run() {
System.err.println("!!!!!!!!!!! task run");
generate();
}
}
@Override
public void afterPropertiesSet() throws Exception {
Management.removeBeanOrFolder(getBeanName(), this);
Management.addBean(getBeanName(), this);
timerTask = new TimingTask();
timer.schedule(timerTask, 30 * 1000);
init();
}
private void init() {
channelOpened = false;
}
@ManagedOperation
public void generate() {
// TODO Auto-generated method stub
String[] wordArray = {"WORD1", "WORD2", "WORD3", "WORD4"};
int idx= 0;
while(true) {
if (channelOpened) {
JetstreamEvent event = new JetstreamEvent();
event.setEventType("SampleEvent");
event.put("data", a[idx]);
fireSendEvent(event);
idx= (idx+ 1) % wordArray.length;
}
try {
Thread.sleep(1 * 500);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
@Override
public void close() throws EventException {
super.close();
shutDown();
}
@Override
public void flush() throws EventException {
}
@Override
public ChannelAddress getAddress() {
return null;
}
@Override
public int getPendingEvents() {
return 0;
}
@Override
public void open() throws EventException {
super.open();
channelOpened = true;
}
@Override
public void pause() {
close();
}
@Override
protected void processApplicationEvent(ApplicationEvent event) {
}
@Override
public void resume() {
open();
}
@Override
public void shutDown() {
}
}
위의 코드에서 관심있게 봐야 할 부분은 afterPropertiesSet method와 open method이다.
afterPropertiesSet method
afterPropertiesSet method는 이름 그대로 Processor가 properties를 설정한 직후 호출되는 method이다. 초기에 설정 등이 필요한 부분은 여기에서 처리하면 된다.
open method
Channel이 열릴때 호출되는 method이다.
매우 간단한 코드이기 때문에 약간의 시간만 투자하면 파악할 수 있다. afterPropertiesSet method에 보면 Management.removeBeanOrFolder를 한 후 다시 Management.addBean을 하는 것을 볼 수 있다. 이건 Pulsar 예제에서 이렇게 사용하고 있어서 똑같이 넣어준 것이다. (왜 remove한 후에 add한 것인지 이유는 모름 -_-)
실행하기
Jetstream을 실행하기 위해서는 먼저 Zookeeper가 동작중이어야 한다. 그리고 실행할 때 설정해줘야 하는 정보는 다음과 같다.
- Main Class : com.ebay.jetstream.application.JetstreamApplication
- arguments : -p 8009 -n appname -cv 1.0
-p : 모니터링 포트
-n : App 이름
-cv : Config 버전, Config를 사용하지 않을때는 그냥 1.0 정도로 넣으면 된다.
- VM arguments : -Djetstream.runtime.zkserver.host=127.0.0.1 -Djetstream.runtime.zkserver.port=2181 -Djetstream.runtime.netmask=0.0.0.0/0
jetstream.runtime.zkserver.host : Zookeeper Host
jetstream.runtime.zkserver.port : Zookeeper Port
jetstream.runtime.netmask : Listen할 netmask
- 시스템 환경변수
JETSTREAM_HOME : appwiring.xml이 위치하는 buildsrc 디렉토리의 경로
MONGO_HOME : Mongodb의 접속 주소, Config를 사용하지 않을때는 설정하지 않아도 된다.