이번 글에서는 E2E-Monitor 개발에 사용했던 웹기술들에 대해서 적어 볼까합니다.
기술적인 내용 보다는 해당 기술들을 사용하기 전까지 어떤 고민들을 했고, 그 고민들을 해결하기 위해서 어떤 기술들을 살펴봤는지, 그리고 최종적으로 왜 해당 기술을 사용하기로 결정했는지 등의 도입 배경 및 사용 후 소감 등을 중점적으로 다루도록 하겠습니다.
E2E- Monitor에 사용했던 웹기술들
E2E-Monitor 중에서도 운영자가 실제로 사용하게 되는 User Client는 Web Application으로 구현되었습니다.
개발에 사용했던 기술들은 다음과 같습니다.
1. jQuery
2. AngularJS
3. RequireJS
4. Bootstrap (for AngularJS)
5. D3.js
6. Dagre-D3
7. C3
8. Big Scatter Chart

1. jQuery
jQuery는 워낙 유명한 JavaScript Framework이기 때문에 따로 설명이 필요없을 것 같습니다.
이번에는 주로 간단한 DOM 제어 기능과 애니메이션 효과등을 구현하는데 사용했습니다.
기본 Framework로 사용한 AngularJS에서도 jqLite(jQuery 호환 API)를 지원합니다만, jqLite 대신 Original jQuery를 사용하는 것이 프로젝트를 진행하는게 더 효율적이겠다고 판단했습니다.
아무래도 필수 기능 몇가지만 지원하는 jLite 보다는 jQuery의 모든 기능을 다 쓸 수 있는 환경이 개발에는 더 도움이 될것 같았고, jQuery 기반의 UI Component들을 사용해야 되는 상황이 있을 수도 있겠다고 생각했었던 것 같습니다.
결과적으로는 역시 jQuery를 사용하기로 했던 것이 좋은 결정이었다고 생각됩니다.
지금 코드를 보면 jQuery 구문이 사용된 코드가 실제로는 그렇게 많지는 않습니다.
하지만 jQuery로 작성된 부분을 AngularJS나 다른 방식으로 처리를 해야 했다면 지금 보다 훨씬 더 복잡한 코드가 되지 않았을까 생각합니다.

2. AngularJS
이번 프로젝트를 진행하면서 처음으로 접했던 Javascript Framework 입니다.
(사실 jQuery와 D3, Bootstrap 말고는 다 처음 접한 기술들 입니다.)
고객사의 Admin Application이 AngularJS를 기반으로 만들어져 있었기 때문에, 시스템 통합을 위해서는 선택의 여지가 없었죠.
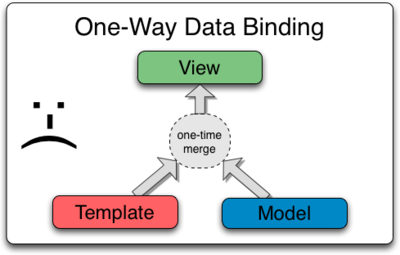
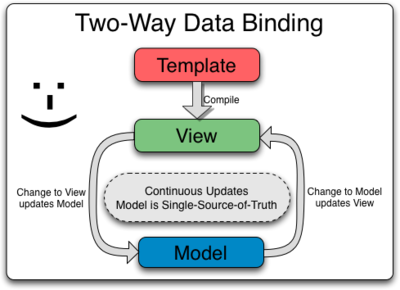
AngularJS는 MVC 또는 MVVM 을 위한 Web Application Framework 입니다.
Data와 View, 그리고 둘사이를 연결해주는 Control를 분리함으로써 Application을 모듈화하고 체계적으로 설계할 수 있도록 도와주는 Library라고 생각하시면 될것 같습니다.
AngularJS에 대한 보다 자세한 기술적인 내용은 저희 개발팀 막내가 작성한 글, "주니어의 개발자 경험기 [1편-AngularJS]"을 참고하시기 바랍니다.
다른 대부분의 IT 기술들도 그렇겠지만 AngularJS를 처음에 접했을 때는 참 쉽다는 인상을 받았는데, 역시 사용하면 할수록, 파고 들면 들수록 어려워지면서도 어느순간 폭 빠져있는 저를 발견하게 되었습니다.
익숙해지기만 한다면, 속된 말로 "떡이 되기 쉬운" Web Application Code를 어느 정도 정리하고 체계화 시킬 수 있는 좋은 Library인것 같습니다. (개발 속도 향상은 덤?)
jQuery와 더불어 Web Application 개발에 꼭 사용해야 될 Javascript Library를 꼽는 다면, 저는 앞으로 AngularJS를 선택하겠습니다.
하지만 Application의 성능이라는 측면에서 본다면, 다수의 접속자를 위한 Web Application에는 적합하지 않은 기술 일 수 있습니다.
필요한 곳에만 부분 적용하는 것도 가능하긴 하지만, 기본적으로 AngularJS를 기반으로 개발된 Web Application들은 Javascript Engine이 HTML DOM을 실시간으로 생성하는 방식이기 때문에, Core HTML Page보다 느릴 수 밖에 없습니다.
개발 속도와 코드 관리의 효율성을 선택할 것인가, 서비스의 품질(특히 반응속도)를 선택할 것인가를 잘 분석하고 판단한 다음, AngularJS 도입에 대해 고려하는 것이 좋을 것 같습니다.

3. RequireJS
사실 RequireJS는 프로젝트 중간에 필요에 의해서 사용했다가 마지막 통합 단계에서 RequireJS 때문에 통합이 불가능하게 되면서 다시 모두 걷어낸 Library 입니다. (전문 용어로 삽질이라고 하죠)
RequireJS는 AMD(Asynchronous module definition) 스팩을 실제로 구현한 Library입니다.
Javascript의 범용성과 표준안을 확립하기 위한 여러 활동 중에서도 Browser 환경(Asynchronous 환경)에 집중해 표준안을 만드는 곳이 AMD라는 곳이구요. 거기에서 내놓은 표준안을 그대로 구현한 Library가 RequireJS입니다.
보다 자세한 내용을 알고 싶으신 분들은 "Javascript 표준을 위한 움직임: CommonJS와 AMD"를 읽어보시는게 좋을 것 같습니다.
프로젝트 중간에 RequireJS를 고려하게 된 이유는 Javascript 파일들의 로딩 순서에 문제가 발생했기 때문입니다.
Web Application을 개발하다 보면 수많은 Javascript 파일들이 생기게 되고 이 js 파일들은 HTML에 <script> 태그를 통해 Web Application에 추가 되게 됩니다.
Browser는 HTML 적혀 있는 순서대로 js 파일 로딩을 시작하게 됩니다.
하지만 네트워크 환경에서는 반드시 시작 순서대로 로딩이 끝난다는 보장이 없죠.
여기서 문제가 발생하게 됩니다. 필요한 js파일의 로딩이 늦어지는 경우가 불특정하게 발생하게 되고, 이런 현상은 바로 에러 상황으로 이어지게 됩니다.
결국 사용자는 잘 되다 안 되다 하는 불안한 Web Application을 접하게 되겠네요.
이런 문제를 해결하기 위해 도입했던 기술이 RequireJS였습니다.
RequireJS는 비동기 방식으로 필요한 js파일을 로딩하는 것이 가능합니다.
각각의 js 파일마다 dependency를 설정할 수 도 있습니다.
RequireJS를 사용하면 HTML문서에서 <script>태그를 이용하는 대신, 필요한 js파일을 Javascript code에서 require() 함수를 이용해 추가할 수 있습니다.
Javascript code에 집중할 수 있으며, 모듈화가 가능하게 되는 잇점을 가질 수도 있습니다.
하지만, 자칫 잘못하면 Callback의 수렁에 빠지는 수도 있으니 조심해야 합니다.
개인적인 느낌으로는 Code 가독성도 상당히 나빠지는 것 같습니다.
프로젝트 마지막에 RequireJS를 다시 모두 걷어 내야 했던, 이른바 "삽질"을 하게 된 이유는 어이 없게도 RequireJS로 인해 통합이 불가능하게 되었기 때문입니다.
RequireJS 기반 Application은 모든 코드가 RequireJS 베이스에서 작성되고 작동되어야 합니다. 그래서 RequireJS 기반이 아닌 Legacy System과는 통합이 불가능 했던 것입니다.
어쩔수 없이 RequireJS를 걷어내는 삽질을 할 수 밖에 없게 됩니다.
그래서 모든 문제가 해결이 되었을까요?
당연히 아니죠....
RequireJS를 도입해서 해결했던 문제(간헐적 에러 발생)가 다시 발생합니다.
결국 해결은 마음에 들진 않지만, 무식한 방법을 사용했습니다. Dependency 가 있는 js 파일들을 하나의 파일로 통합해 버렸습니다. ㅡㅡ;;;;
지금 생각해 보면 lazy load 같은 기법을 사용했으면 깔끔했을 것 같은데, 그 때 당시는 맨붕상태였기 때문에 일단 가능한 쉽고 빠른 방법을 찾을 수 밖에 없었습니다.
그 때 당시의 삽질이 기억나 다소 감정적인 글이 되어 버렸는데, 혹시나 저희와 비슷한 상황에서 RequireJS를 고려하시는 분들이 혹시라도 계신다면 이 글이 조금이나마 도움이 되길 바랍니다.

4. Bootstrap(for AngularJS)
Bootstrap은 반응형, 모바일 웹앱을 위한 HTML, CSS, JavaScript 통합 Framework라고 소개 되고 있지만, 저는 개인적으로 HTML계의 jQuery 정도의 위치를 가지는 기술이라고 생각합니다.
jQuery의 모토인 "최소한의 Javascript code로 최대의 효과를 내기 위한 Framework (Write less, do more)"에서 "Javascript"라는 단어를 "HTML"로 바꾸면 딱 Bootstrap에 어울리는 설명이 되는 것 같거든요.
실제로 Bootstrap을 사용하면 적은 HTML 코드로 훌륭한 Web UI를 구현할 수 있습니다.
그리고, 미적 감각이 상대적으로 떨어지는 개발자라도 Bootstrap을 사용하는 것 만으로도 어느 정도 그럴듯한(?) 결과물을 얻을 수 있기 때문에, 요즘 Web Application 개발자들 사이에서는 거의 필수 요소가 되어가고 있는것 같습니다.
이번 프로젝트에서도 디자이너의 부제 및 개발 기간 단축을 위해 사용하게 되었는데, AngularJS를 기본으로 사용하는 Application에서는 Original Bootstrap를 사용할 수 없는 문제가 있었습니다.
다행히도 AngularJS용 BootStrap이 따로 있어서 그걸 사용하게 되었는데, 일반 Bootstrap의 사용법과는 약간 다른 부분들이 있기 때문에 익숙해 지는데 시간이 조금 필요했던것 같습니다.
프로젝트 마지막 통합 과정에서 RequireJS와 함께 Bootstrap도 문제가 되었습니다.
RequireJS 같은 경우는 하루 정도의 삽질로 끝이 났지만, Bootstrap 같은 경우는 해결하는데는 사흘이 넘는 시간이 걸렸던것 같습니다.
문제가 되었던 부분은 고객사가 사용하는 UI Library와 Bootstrap과의 총돌이었는데, 고객사에서는 Bootstrap 코드를 약간 수정해서 고객사 전용 UI Component를 사용하고 있었습니다.
그런데 고객사가 사용했던 Bootstrap의 버전과 저희가 사용했던 Bootstrap의 버전이 서로 달랐던것 같습니다.
저희 Bootstrap용 js 파일을 추가하면 다른 화면들이 모두 깨지고, 고객사의 Bootstrap 파일을 그대로 사용하면 우리가 만든 Application의 화면이 깨지는 문제가 발생했습니다.
버전따라 사용법이 서로 달랐던 것 같습니다.
결국 고객사의 UI용 js파일을 사용하고 저희 Application은 수정하기로 결정하고, 고객사의 bootstrap.js 소스코드를 분석하면서 깨지는 UI Component들을 하나씩 수정하는 삽질을 했습니다.
충돌나는 부분을 jQuery UI로 변경하는 것으로 해결 할 수도 있었는데, 그렇게 하면 Lock & Feel 이 안 맞을 수 있기 때문에 그 때 당시에는 선택할 수 없었습니다.
결국은 프로젝트 완료 후 코드 관리의 효율성을 위해 Bootstrap UI 중에서 충돌이 났던 Component들을 모두 jQuery UI로 변경하는 작업을 다시 한번 수행하게 됩니다.

5. D3.js
D3.js는 Data Visualization Javascript Framework입니다.
단순하게 Web에서 Graph를 그리기 위한 Library라고 생각하실 수도 있지만, 그것보다는 훨씬 강력한 기능들을 가지고 있는 Framework입니다.
가령, 전국의 현재 기온을 한눈에 볼 수 있는 Bar Chart가 있다고 생각해 봅시다. 전국의 현재 기온을 표로 보는 것보다는 Bar Chart로 보는 것이 휠씬 보기도 좋기 이해도 잘 될거라고 생각합니다.
여기서 조금만 발전 시켜 보죠.
기존 Bar Chart에 하룻동안의 기온 변화를 애니메이션로 표현하는 기능을 추가해 보면 어떨까요?
원래는 지역과 기온, 이렇게 두가지의 정보를 가지고 있던 그래프에 시간이라는 정보를 추가하는 거죠.
Bar Chart 하단에 시간을 선택할 수 있는 스크롤바가 있고, 그 스크롤바를 마우스로 드래그 할때 마다 Bar Chart가 변하게 하면 될 것 같습니다.
전국의 기온을 한눈에 볼수 있을 뿐만 아니라 하룻동안의 기온차를 시각적으로 볼수 있는 새로운 Graph가 탄생했습니다.
Data Visualization이라는 것은 알고 보아왔던 형태의 그래프 뿐만 아니라, 다양한 아이디어와 기술을 적용해 새로운 정보를 재생산하는 기술입니다.
그리고 D3.js는 이러한 Data Visualization을 실제로 웹에서 구현할 수 있도록 다양한 API를 제공하는 Library입니다.
이번 프로젝트에서는 사실 D3.js를 직접적으로 사용하지는 않았습니다.
D3.js를 기반으로 한 다른 Library들을 사용하기 위해서 프로젝트에 포함한 거라서, 사실 사용 소감이라고 적을만 한 것이 없네요.
그래도 개인적으로 관심있는 분야라 D3.js에 대해서는 따로 카테고리를 만들어서 연재해 볼까 생각하고 있습니다.

6. Dagre-D3
Dagre-D3는 Directed Graph(방향 그래프)를 쉽게 그릴 수 있는 Javascript Library 입니다. D3 기반으로 작성되어 있기 때문에 D3.js가 기본으로 필요합니다.
Server Map을 Directed Graph로 그려야 해서 도입한 기술입니다.
Directed Graph를 지원하는 Javascript Library가 몇가지 있었지만, 대부분 범용으로 Diagram을 그릴 수 있는 것들이었고, 저희는 Directed Graph만 그리면 되었기 때문에 Directed Graph에 특화된 Dagre-D3를 선택하게 되었습니다..
Dagre-D3를 사용함으로써, 쉽고 빠르게 일정 수준 이상의 퀄리티를 가지는 결과물을 얻을 수 있었던 것 같습니다.
Directed Graph가 프로젝트의 메인 기능이었기 때문에 전체 프로젝트에서 작업 시간도 가장 많이 할당했었고, 삽질도 가장 많이 한 기능이긴 합니다.
하지만, 여전히 고객사의 다양한 요구사항을 모두 충족시키기에는 기능이 부족했던 것도 사실입니다.
(예를 들어 그룹핑 되어 있는 노드를 펼쳤을 때 노드의 배치가 이쁘지 않다던지 하는....)
결국 요구사항을 모두 충족 시키기 위해서는 D3.js를 사용해 직접 Directed Graph를 구현할 수 밖에 없을 것 같습니다.
물론 시간과 비용이 그만큼 더 들어가겠죠.
현실적으로는 여러 Library들의 기능들을 파악 한 다음에 요구사항을 타협해서 적당한 Library를 선택해서 사용하는 것이 개발사나 고객사 모두에게 좋지 않을까 생각합니다.
Dagre-D3의 장단점을 나열 하자만 다음과 같습니다.
1. 장점
- 안정적인 Rendering 속도
- 사용법이 간단하다.
- Layout만 지정해 주면 노드들은 알아서 배치해 준다.
- 원하는 대로 수정할 수 있을 만큼 충분히 다양한 디자인 요소를 제공해 준다.
- 노드를 Group으로 묶는 것이 가능하다. ()
2. 단점
- 사용자가 마음대로 노드를 움직할 수 없다.
- 실시간으로 Layout을 바꾸는 것은 불가능하다.
- 노드를 그룹핑하고 푸는 것도 당연히 가능하지만, 풀었을 때 노드들의 배치가 엉망이다. (이쁘지 않다)
- 노드들의 위치를 고정할 수 없다. (새로운 노드가 추가되거나 기존 노드가 삭제되면 전체적인 배치가 다 바뀌어 버린다)
더 자세한 내용은 "주니어 개발자의 경험기 [2편 - Javascript 시각화 라이브러리]" 를 보시면 될 것 같습니다.

7. C3
D3 기반 Chart 지원 Library 입니다.
선그래프, 막대그래프,파일그래프 등 일반적인 형태의 Chart들을 그리기 위해 사용했습니다.
C3.js에 대한 내용은 "주니어 개발자의 경험기 [2편 - Javascript 시각화 라이브러리]" 를 읽어보시는게 더 좋을 것 같네요.

8. Big Scatter Chart
Scatter Chart(분산,분표도 그래프)는 API Call의 응답 시간을 한눈에 보기 위한 용도로 사용했습니다.
X축은 시간(24시간), Y축은 응답시간으로 호출 하나 마다 그래프에 점을 하나씩 찍어 그리는 그래프 입니다.
원래는 Jennifer에서 X-View라는 이름으로 동일한 기능을 지원하는 Library를 제공하고 있습니다.
Jennifer 뿐만 아니라 Scatter Chart를 지원하는 Library는 몇가지 있었는데, 그 Library들의 공통된 문제점은 HTML5의 그래픽 요소인 Canvas와 SVG중 상대적으로 느린 SVG를 사용한다는 것이었습니다.
백터 기반의 SVG는 다양한 그래픽 요소를 자유롭게 표현하기에 적합하지만, CPU 연산에 의존해 이미지를 생성하기 때문에 픽셀 기반의 Canvas 보다 느린 문제점이 있습니다.
실제로 SVG 기반의 Scatter Chart Library를 사용해 본 결과 고객사의 요구사항을 충족하긴 힘들었습니다.
(하룻동안의 데이터를 모두 출력하기 위해서는 Scatter Chart는 약 8천만건의 Dot를 한번에 찍어야 함)
그래서 구글링중 발견한 것이 Big Scatter Chart 입니다.
찾고 보니 Pinpoint에서도 사용하고 있는(사실은 Pinpoint에서 사용할려고 만든) Library 더군요.
Canvas기반의 Library로 다양한 사용자 Interaction을 지원하지는 못하지만, 대량의 데이터를 표현하는데는 훌륭한 성능을 보였습니다.
Dagre-D3.js에 대한 기술적인 내용은 "주니어 개발자의 경험기 [2편 - Javascript 시각화 라이브러리]" 에 잘 정리되어 있습니다.
이번 프로젝트를 진행하면서 전체적으로 느꼈던 점은, 이제 정말 데이터 레이어와 프리젠테이션 레이어가 확실히 분리되어 가고 있으며, 프리젠테이션 레이어쪽 기술들이 많이 정리가 되어가고 있는 것 같다는 인상을 받았습니다.
PHP로 데이터에서부터 HTML문서까지 모두 작업하던 시대와는 참으로 많이 달라진것 같습니다.
아마 AngularJS를 통해 Javascript code 단이 깔끔하게 정리되는 것을 보면서 더 그렇게 느꼈던 것 같습니다.
항상 Javascript와 관련된 새로운 기술들을 접하면 두렵기도 하면서 한편으로는 신나기도 하는 것는 것이, 역시 저는 Javascript 오덕이었던 듯 합니다.
(그래도 Callback의 수렁은 정말 싫습니다.)
다음 글은 E2E-Monitor의 Back-end 기술들을 살펴 보도록 하겠습니다.
긴글 읽어 주셔서 감사합니다.