
이전에 Pulsar 설치와 실행에 대하여 포스팅을 하였는데, 이번에는 Pulsar에서 제공하고 있는 Pulsar White Paper를 간략하게 정리해보도록 하겠다. 원문은 아래 링크에서 확인 가능하다.
Pulsar White Paper 원문 보러 가기White Paper
1. Introduction
User behavior event는 user-agent 또는 IP주소와 같은 많은 정보들을 가지고 있다. eBay에서는 다량의 event들을 처리하고 있는데, BOT이 생성한 event들을 걸러내어 처리할 수 있다.
이 문서에서는 Pulsar의 data pipeline에 대한 디자인을 제안한다. 계산 대부분을 CEP 엔진을 사용하여 고가용성의 분산처리 시스템을 구축하였다. 우리는 이벤트 스트림을 데이터 베이스 테이블처럼 사용하는 것을 제안한다. Pulsar는 SQL 쿼리가 데이터 베이스 테이블을 사용하는 것처럼 실시간 스트림에대해 집합을 생성하는 것을 가능하게 한다. 이 문서에서는 Pulsar에서 이벤트 스트림을 처리할 때 이벤트를 보완하게 하고, 필터하고, 변화시키는 방식에 대해서 설명하였다.
2. DATA AND PROCESSING MODEL
2.1 User Behavior Data
사용자 행동 데이터의 예측이 불가능한 패턴이 초당 100만 개가 넘게 생산된다. 이러한 데이터를 빠르게 처리하기 위해 in-memory 처리 방식을 해야 한다.
2.2 Data Enrichment
BOT 데이터들은 필터로 거른다. 필터링을 거친 데이터를 지역, 기기, 인구 통계 등의 데이터로 좀 더 풍부하게 만든다.
2.3 Sessionization
관련된 이벤트를 공통된 키로 구분하여 그룹핑해주는 상태 관리 프로세스이다.
2.4 User defined partial views of original streams
event들의 dimension이 아주 많지만 실제 사용자들은 원하는 특정 demention만 원하기 때문에 사용자들이 설정할 수 있게 하였다.
2.5 Computing aggregates in real-time for groups of multiple dimensions
다양한 dimension을 그룹화 하기 위해서 실시간으로 summary data를 산출 한다.
2.6 Computing Top N, Percentiles. and Distinct Count Metrics in real time
distinct count와 percentile을 구하기 위하여 HyperLogLog와 TDigest라는 알고리즘을 사용하여 공간과 시간을 절약한다. 이 알고리즘들은 근사 알고리즘으로써, 1%대의 에러를 가지는데, 이는 통계학적으로 문제없음이라고 판단한다.
2.7 Dealing with out of order and delayed events
이벤트가 비정상이거나 지연되는경우, 롤업기능으로 처리 가능하다.
3. ARCHITECTURE
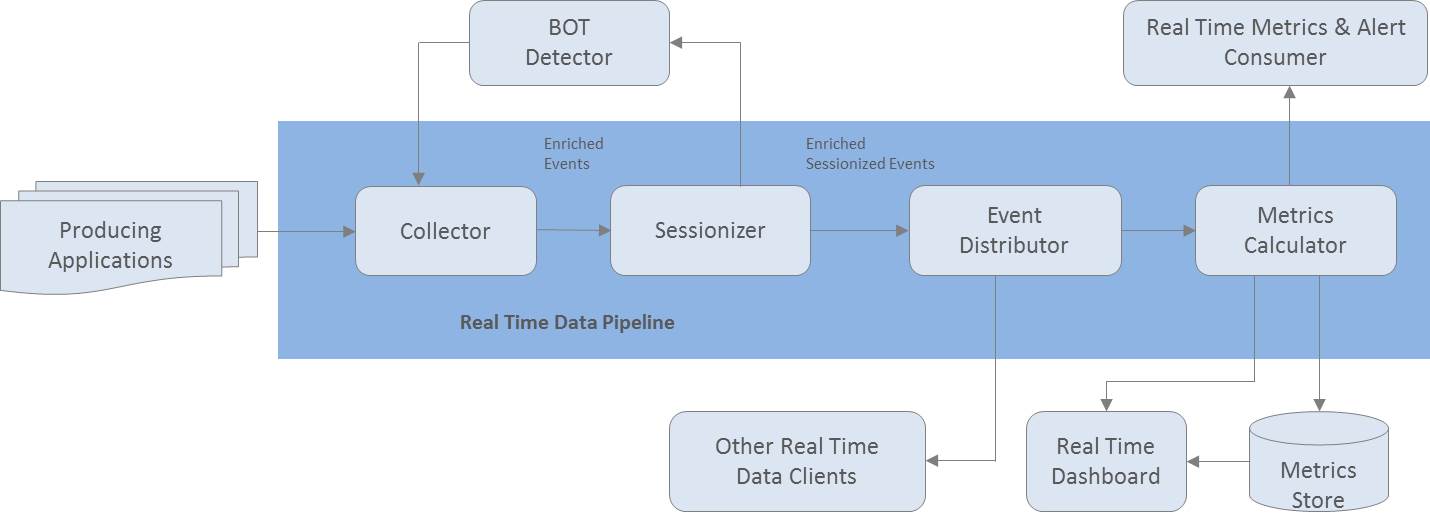
<Fig. 1. Real-time Data Pipeline>
3.1 Complex Event Processing Framework
Jetstream 은 Spring으로 작성한 CEP 엔진으로써, 모든 pulsar의 real-time pipeline은 Jetstream으로 작성하였다. Jetstream은 다음과 같은 기능이 탑재되어있다.
1. 처리 로직을 서술적 SQL로 정의할 수 있다.
2. 어플리케이션 재시작이 필요없는 Hot deploy SQL.
3. Annotation 플러그인 프레임워크를 사용하여 SQL 기능성을 증대시킨다.
4. SQL을 사용하여 pipeline을 타고 전달한다.
5. SQL을 사용하여 stream affinity를 동적으로 생성할 수 있다.
6. Spring IOC를 사용한 Declarative pipeline stitching은 런타임에 동적 토폴로지 변경을 가능하게 한다.
7. Esper의 통합기능을 통한 CEP 기능.
8. elastic scaling이 되는 Clustering.
9. Cloud deployment가 가능한다.
10. push pull 모델을 사용한 pub-sub messaging기능을 가지고 있다.
3.2 Messaging
3.2.1 Ingest Messaging
REST interface를 사용하여 이벤트를 받아서 처리한다.
3.2.2 Push vs. Pull Messaging
push messaging과 Pull messaging의 장단점이 있기 때문에 어떤것을 선택해야 할 지에 대해 고민하였다.
3.2.3 Messaging Options
Messaging은 하이브리드로 구현하기로 하였다. Jetstream은 kafka를 사용하여 pub-sub cluster messaging을 할 수 있게 하였다.
4. REAL-TIME PIPELINE
4.1 Collector
Real-time pipeline의 첫 번째 단계. Jetstream CEP엔진이 있는 곳이다. 이벤트를 REST interface로 받아서 처리한다. CEP엔진은 BOT 이벤트들을 필터링해준다.
4.1.1 Geo and Device Classification Enrichment
BOT 이벤트들이 걸러내진 이벤트들에 지역 정보를 추가한다.
4.2 Bot Detector
BOT signature cache에 등록된 패턴을 걸러내도 그 외의 패턴들은 걸러내기 쉽지 않다. 하지만 CEP엔진으로 BOT의 특징을 잡아내어 BOT signature cache에 등록하여 Collector가 BOT을 걸러낼 수 있게 한다.
4.3 Sessionizer
Real-time pipeline의 두 번째 단계이다. 이 단계의 주된 기능은 tenancy based sessionization 을 지원하는 것이다. Sessionization 은 session 기간에 특정 식별자를 포함하는 이벤트의 임시 그룹핑 과정이다. 유니크한 식별자의 이벤트가 처음 탐지되면 각 window는 시작된다. 이 window는 이벤트가 더 들어오지 않으면 끝나게 된다.
4.3.1 Session Meta Data, Counters and State
이벤트가 도달하면, 세션당 메타데이터, 빈도수 계산 및 상태를 관리한다. 모든 처리 로직은 SQL로 작성되었다.
4.3.2 Session Store
Backing store에 back up 되는 local off-heap cache에 세션 레코드를 저장하였다. Sessionizer 에서는 cache entry에 TTL을 세팅 가능하고 해당 entry가 만기 되었을 때 정확한 알림을 받을 수 있어야 하는 것이 필요하였다. 그래서 특별한 off-heap cache를 개발하였다.
4.3.3 Session Backing Store
Session Backing Store를 위해, 다음의 사항들을 고려하였다.
a. local read, write, delete 지원
b. local cross data center replication 지원
c. eventual consistency 지원 (고가용성을 달성하기 위해 분산 컴퓨팅에 사용되는 일관성 모델이다. 데이터에 새로운 업데이트가 이루어지지 않은 경우, 마지막으로 업데이트된 값을 반환하는 것을 비공식적으로 보장한다.
d. 저장 항목에 대한 life cycle을 관리한다. (TTL 지원)
e. 쓰기와 읽기의 비율을 10:4로 지원한다.
f. 초당 읽기 쓰기를 1M까지 지원한다.(Scale to)
g. 변수 크기는 200bytes에서 50Kbytes까지 지원한다. (Scale well)
h. Cloud에서 배포를 선호한다.
i. 주어진 클라이언트 노드에서 삽입된 키의 범위를 조회하기 위하여 보조 인덱스를 만든다.
위의 사항을 충족시키는 적합한 Session store를 찾기 위하여 Cassandra, Couchbase, 자체 개발database를 비교했다. Cassandra와 Couchbase는 Disk기반 솔루션이었기 때문에, in-memory방식이 필요한 우리는 자체 개발 database를 Session store로 선택하였다.
4.3.4 SQL extensions
Jetstream은 Esper의 SQL 언어를 확장하기 위하여 사용자들이 원하는 annotation을 작성할 수 있게 annotation 플러그인 프레임워크를 제공한다.
4.4 Event Distributor
pipeline의 세 번째 단계이다. 이 단계의 주 기능은 pipeline subscriber의 커스텀 뷰를 생성하게 하는 것이다.
4.4.1 Event filtering, Mutation and Routing
이벤트들은 SQL 문법으로 변화시키고 필터링하고 전달할 수 있다. 또한, annotaion을 사용하여 이벤트가 지나갈 루트를 지정해줄 수 있다.
4.5 Metrics calculator for Multi-dimensional OLAP
Metrics Calculator는 다양한 dimension과 time series data를 생산하는 사용자 정의의 metrics를 계산하는 실시간 metric computation engine이다. Metrics Calculator는, multiple dimension을 그룹핑하여 추출할 수 있는 SQL쿼리를 실행 할 수 있게 인터페이스를 제공해준다. 이 단계에서는 이벤트를 SQL로 컨트롤 가능하다.
4.5.1 Harvesting Metrics
이벤트들은 random scheduling이나 affinity based scheduling을 통해 Metrics Calulator application cluster에 스케쥴 될 수 있다. Metrics는 short tumbling wondows(10초동안) live stream에서 추출 된다. Window가 진행되고 있을때 unique dimension grouping을 위해 metric event가 생산된다.
4.5.2 Aggregating across the Metrics Calculator cluster
SQL문과 annotation을 사용하여 여러노드간의 aggregation이 가능하다.
4.5.3 Creating rollups in time series database
time series data를 생성하여 DB에 저장하거나 실시간 dashboard에서 widget으로 보여준다.
4.5.4 Metric Store
Metric Store를 하기 위하여 아래의 DB들을 비교해 보았다.
Open TSDB vs. Cassandra vs. DRUID
|
Open TSDB |
Cassandra |
장점 |
빠른 데이터 수집 |
빠른 데이터 수집 |
단점 |
Rollup생성 불가 |
group by 와 집합함수를 지원하지 않음 |
Pulsar는 필요조건을 충족시키기 위하여 DRUID를 사용하였다.
5. CONCLUDING REMARKS
이 문서에서는 Pulsar를 구현할 때 고려했던 부분들의 일부이다. 실시간으로 사용자 행동분석과 관련된 문제들을 위하여 데이터와 프로세싱모델에 관해 설명하고 있다. Pulsar는 eBay cloud에서 1년간 사용되었다. 0.01% 미만의 안정적인 유실로 초당 10만 개의 events들을 처리했다. 95퍼센타일로 pipeline의 end to end 지연은 100ms 미만이다. 99.99%의 가용성으로 파이프라인을 성공적으로 구동시켰다. eBay의 몇몇 팀은 성공적으로 우리의 플랫폼을 사용하여 in-session 개인화, 광고, 인터넷 마케팅, 빌링, 비지니스 모니터링 등 많은 문제에 대한 해결책을 찾았다.
Pulsar의 주요 사용처는 사용자 행동 분석에 포커스를 맞추고 있지만, Pulsar를 실시간 처리가 요구되는 많은 다른 사용 경우에 대해서 쓰이기를 원한다.
White Paper에서는 실제로 eBay에서 Pulsar를 사용하여 사용자 행동분석 패턴을 분석하여 여러 가지 문제들을 해결하였다고 서술하고 있다. 또, Pulsar는 빠르고 신뢰도 높은 데이터 처리를 할 뿐만 아니라 실시간으로 데이터 분석이 가능함을 강조하였다. 그 기반은 Jetstram이라는 독자적인 플랫폼이고, 익숙한 SQL문과 annotation을 사용하여 데이터 분석이 가능함을 설명하고 있다.
White Paper가 아주 상세한 부분까지는 서술하고 있지 않지만, 어떤 데이터들을 어떻게, 무엇을 사용하여 처리하는가에 대한 궁금증을 풀 수 있기에는 충분한 것 같다. 자세한 쿼리 예제나 구조가 궁금하면 Pulsar 공식홈페이지에서 확인할 수 있다.
마치며...
번역과 이해를 같이 해야하여 어려웠지만, 실시간 데이터 분석 툴의 구조를 나름은 자세히 알 수 있게 되어 의미있는 시간이었음을 상기하며, 이번 포스팅은 여기에서 마친다.
참고자료: http://gopulsar.io/docs/Whitepaper_Pulsar_Real-timeAnalyticsatScale.pdf
'Real-time Big Data' 카테고리의 다른 글
| Storm-ESPER vs eBay Pulsar : 비용, 안정성, 확장성에 대한 비교 (0) | 2015.06.17 |
|---|---|
| eBay Pulsar 분석 - Pulsar Demo 실행을 통한 이해 (0) | 2015.06.10 |
| Pulsar - 실시간 분석 플랫폼 : 설치 및 실행편 (0) | 2015.05.27 |
| Storm-Esper 성능 테스트 (1) | 2015.04.16 |
| eBay Pulsar: real-time analytics platform (0) | 2015.03.13 |
