Storm-ESPER는 Storm과 ESPER를 이용한 실시간 데이터 처리 엔진이다.
Storm-ESPER에 대해 궁금하다면, 엠비안에서 진행했던 Strom-ESPER 프로젝트의 Prototype과 테스트에 대한 블로그에서 참조 할 수 있다. (Storm & Esper Prototype 및 Test)
Storm-ESPER 프로젝트를 받았을 때, 프로젝트에 대한 프로토타입 테스트 결과문서, 설치문서, 설치 패키지가 존재하였다. 하지만 패키지와 문서가 CentOS를 위한 것이었기 때문에, 내 작업환경인 Ubuntu에서 실행되지 않았다. 그리하여 Storm-ESPER실행을 위한 각 모듈을 따로 컴파일하여 실행시켜줘야하는 번거로움이 있었다. 그뿐만 아니라 실행하는 과정에서 컴파일러 버전이 맞지 않거나 실행에 필요한 jar파일들이 없어서 고생하기도 했다.
이러한 실행의 어려움을 해소하기 위해, Storm-ESPER 실행방법을 자세히 설명해 보도록 하겠다.
모든 설치 및 실행방법은 Ubuntu시스템 기준으로 설명한다.
Storm-ESPER 실행전 필요조건 1 - 필요한 프로그램 설치
1. zookeeper-3.4.6
압축파일을 미러에서 받은 후 압축을 푼다.
$ wget http://mirrors.ukfast.co.uk/sites/ftp.apache.org/zookeeper/stable/zookeeper-3.4.6.tar.gz
$ tar -xvf zookeeper-3.4.6.tar.gz
config 파일을 생성한다.
$ vi conf/zoo.cfg
# The number of milliseconds of each tick
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes.
dataDir=/tmp/zookeeper
# the port at which the clients will connect
clientPort=2181
Zookeeper를 실행한다.
$ ~/zookeeper-3.4.6/bin/zkServer.sh start
2. RabbitMQ Server
RabbitMQ는 repository에서 설치할 수 있다.
$ apt-get install rabbitmq-server
WebUI Admin plugin을 설치하여 모니터링을 할 수 있게 한다. 플러그인 설치 후 리스타트를 해준다.
$ rabbitmq-plugins enable rabbitmq_management
$ service rabbitmq-server restart
3. Apache Storm 0.9.4
압축파일을 미러에서 받은 후 압축을 푼다. (이번 테스트에서 사용한 Storm버전은 0.9.4이다.)
$ wget http://mirror.apache-kr.org/storm/apache-storm-0.9.4/apache-storm-0.9.4.tar.gz
$ tar -xvf apache-storm-0.9.4.tar.gz
conf 파일을 변경해준다.
$ vi ~/apache-storm-0.9.4/conf/storm.yaml
########### These MUST be filled in for a storm configuration
storm.zookeeper.servers:
- zookeeper가 설치되어있는 호스트 ip
# - "localhost"
#
nimbus.host: nimbus가 설치되어있는 호스트 ip
Storm-ESPER 실행전 필요조건 2 - 파일수정 및 Storm 실행
1. conf 파일 수정 및 라이브러리 파일 추가
먼저 Storm-ESPER를 컴파일하기 전에 conf파일을 수정해야한다. "storm-esper"프로젝트의 conf폴더에 있는 yaml파일들을 조건에 맞게 수정해 준다. 아래의 예시를 따라서 본인의 ip를 사용하면 된다.
~/storm-esper/trunk/conf/deploy.yaml
~/storm-esper/trunk/conf/nimbus_conf.yaml
~/storm-esper/trunk/conf/esper_supervisor_conf.yaml
rabbitmq.server.queue.ip: "192.168.0.28"
rabbitmq.server.username: "guest"
rabbitmq.server.userpass: "guest"
3. jar파일 추가
Storm-ESPER엔진을 실행하기 전에 custom scheduler로 EsperBolt를 특정 supervisor(esper-supervisor)에 할당하기 위하여 Nimbus용 jar파일을 생성하여 Storm 라이브러리에 위치시켜야 한다. 또한, Storm-ESPER연동을 위하여 Esper와 RabbitMQ 라이브러리를 Storm 라이브러리에 복사하여야 한다.
Apache Storm 0.9.4가 설치되어있는 폴더 내 lib 폴더에 라이브러리 파일을 추가하는 법은 아래와 같다.
1. "storm-esper-scheduler"프로젝트를 컴파일 하여 jar파일 생성 및 라이브러리 파일 복사
$ cd ~/storm-esper-scheduler/trunk
$ mvn clean dependency:copy-dependencies install
$ cd target
$ cp storm-esper-scheduler-0.0.1.jar ~/apache-storm-0.9.4/
2. "storm_esper" 프로젝트를 컴파일 하여 dependency jar파일 생성 및 라이브러리 파일 복사
$ cd ~/storm_esper/trunk
$ mvn clean dependency:copy-dependencies install
$ cd target/dependency
$ cp amqp-client-3.1.4.jar cglib-nodep-2.2.jar antlr-runtime-3.2.jar esper-4.10.0.jar ~/apache-storm-0.9.4/lib/
4. Storm실행
이제 Storm을 실행할 준비가 되었다. 아래의 명령어로 Storm을 실행한다. 테스트용 실행방법이므로 Nimbus, Supervisor, UI를 전부 한대의 머신에서 실행해 보겠다.
$ ~/apache-storm-0.9.4/bin/storm nimbus &
$ ~/apache-storm-0.9.4/bin/storm supervisor &
$ ~/apache-storm-0.9.4/bin/storm ui &
Strom-ESPER 실행

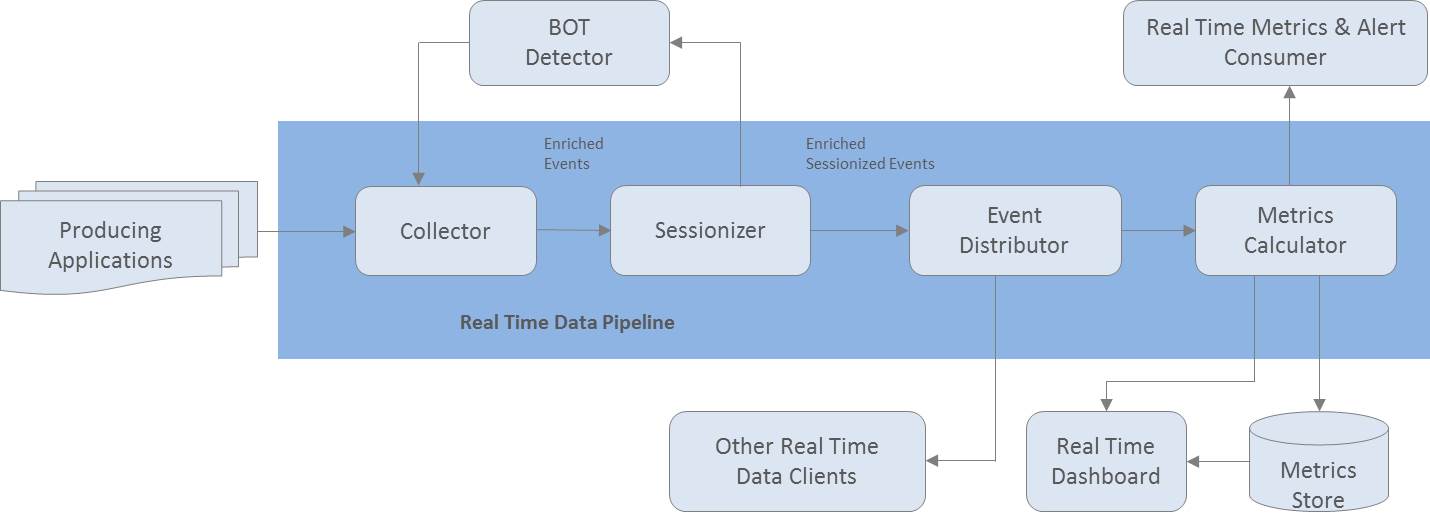
<그림 1. Storm-ESPER 동작 구성도>
1. DataThrower
테스트용 더미 데이터를 DataThrower를 사용하여 RabbitMQ에 전송해야 한다. 더미 데이터는 DataThrower프로젝트를 컴파일하여 생성된 jar파일을 실행하여 "in_queue"에 전송한다. 이때 throw.conf파일의 "inqueueName":"in_queue"로 수정해준다.
$ java -cp ~/maven_data/trunk/target/maven_data-0.0.1-SNAPSHOT.jar com.embian.maven_data.tester.DataThrower ~/maven_data/conf/throw.conf >> ~/maven_data/logs/throw.log
2. submit topology
"storm-esper"프로젝트를 컴파일하여 생성된 토폴로지를 스톰에 올려주는 스크립트를 실행한다.
$ sh ~/storm_esper/trunk/etc/submit_topology.sh
3. EPL command 실행
"storm-esper-client"프로젝트를 다음의 명령어로 컴파일한다.
$ cd ~/storm-esper-client/trunk
$ mvn clean dependency:copy-dependencies install -Dmaven.test.skip=true
첨부된 스크립트를 통하여 사용할 EPL을 적용하면 된다.
$ sh ~/storm-esper-client/trunk/etc/run_tester.sh '{"cmd":"EPL command", "params":{"bolt_id":"볼트 명", "statement":{"name":"커맨드 이름", "body":"EPL 쿼리", "state":"STARTED", "do_output": true/false}}}'
4. DataReceiver
Storm-ESPER가 처리한 데이터는 "out_queue"에 누적된다. DataReceiver는 단순하게 "out_queue"의 데이터를 읽어와서 파일로 저장한다. DataReceiver 프로젝트를 컴파일하여 생성된 jar파일을 실행하여 파일로 저장한다.
$ java -cp ~/maven_data/trunk/target/maven_data-0.0.1-SNAPSHOT.jar com.embian.maven_data.tester.DataReceiver ~/maven_data/conf/receive.conf >> ~/maven_data/logs/receive.log
예제 실행
간단한 예제를 통하여 실행이 잘 되는지 확인해 보자.
시나리오
1. nginx의 access log를 JSON으로 만든 데이터 스트림에서 5분동안 응답시간이 1초가 넘는 Request의 통계를 출력
2. 5분동안 Page A -> Page B -> Page C의 경로로 움직인 IP에 대해서 출력
nginx의 access log를 JSON으로 만든 데이터 스트림 샘플
{"status": "200", "body_bytes_sent": "9784", "remote_user": " ", "request_time": "0.000", "http_referer": "http://www.mmm.com/bbs/board.php?page=A&wr_id=1", "remote_addr": "192.168.1.1", "request": "GET /skin/board/aa.aaa/aa.js/aaa.js?time=1434393200 HTTP/1.1", "http_user_agent": "Mozilla/5.0 (Windows NT 6.1; Trident/7.0; rv:11.0) like Gecko", "upstream_response_time": "-", "time_local": "16/Jun/2015:03:33:20 +0900"}
사용한 command를 초기화 하려면 다음을 실행한다.
$ sh ~/storm-esper-client/trunk/etc/run_tester.sh '{"cmd":"clean", "params":{}}'
0. LogEvent스키마 등록
$ sh ~/storm-esper-client/trunk/etc/run_tester.sh '{"cmd":"add_statement", "params":{"bolt_id":"esper-bolt-1", "statement":{"name":"CreateLogEventType", "body":"create schema LogEvent(status string, body_bytes_sent string, remote_user string, request_time string, http_referer string, remote_addr string, request string, http_user_agent string, upstream_response_time string, time_local string)", "state":"STARTED", "do_output":false}}}'
1. nginx의 access log를 JSON으로 만든 데이터 스트림에서 5분동안 응답시간이 1초가 넘는 Request의 통계를 출력
$ sh ~/storm-esper-client/trunk/etc/run_tester.sh '{"cmd":"add_statement", "params":{"bolt_id":"esper-bolt-1", "statement":{"name":"Senario1-1", "body":"SELECT count(remote_addr) FROM LogEvent.win:time(5 min) WHERE cast(request_time,float) >= 1.000 ", "state":"STARTED", "do_output":true}}}'
2. 5분동안 Page A-> Page B-> Page C의 경로로 움직인 IP에대해서 출력
결과물은 DataReceiver를 통하여 파일로 저장된 내역에서 확인이 가능하다.
시나리오 1. 결과물
--queueServerAddr : 192.168.0.28
--queueName : out_queue
{"newEvents":[{ "count(remote_addr)": 1
}],"oldEvents":[]}
{"newEvents":[{ "count(remote_addr)": 2
}],"oldEvents":[]}
{"newEvents":[{ "count(remote_addr)": 3
}],"oldEvents":[]}
{"newEvents":[{ "count(remote_addr)": 4
}],"oldEvents":[]}
{"newEvents":[{ "count(remote_addr)": 5
}],"oldEvents":[]}
{"newEvents":[{ "count(remote_addr)": 6
}],"oldEvents":[]}
{"newEvents":[{ "count(remote_addr)": 7
}],"oldEvents":[]}
시나리오 2. 결과물
{"newEvents":[{ "target2.remote_addr": "173.254.216.67",
"target2.request": "GET page=C HTTP/1.0"
}{ "target2.remote_addr": "173.254.216.67",
"target2.request": "GET page=C HTTP/1.0"
}],"oldEvents":[]}
{"newEvents":[{ "target2.remote_addr": "203.133.168.168",
"target2.request": "GET page=C HTTP/1.1"
}{ "target2.remote_addr": "203.133.168.168",
}],"oldEvents":[]}
{"newEvents":[{ "target2.remote_addr": "211.53.23.131",
"target2.request": "GET page=C HTTP/1.1"
}{ "target2.remote_addr": "211.53.23.131",
"target2.request": "GET /page=C HTTP/1.1"
}{ "target2.remote_addr": "211.53.23.131",
}],"oldEvents":[]}
{"newEvents":[{ "target2.remote_addr": "66.249.71.111",
"target2.request": "GET page=C HTTP/1.1"
}{ "target2.remote_addr": "66.249.71.111",
"target2.request": "GET page=C HTTP/1.1"
}{ "target2.remote_addr": "66.249.71.111",}],"oldEvents":[]}
간편한 실행이 어려웠고, 새로운 시스템을 학습해가며 접했기 때문에, 꽤 애를 먹은 프로젝트 실행을 거쳤다. 스크립트가 있어서 그나마 편하게 실행을 할 수 있었던 것 같다. 위의 설치 및 실행기는 단독 머신에서 실행을 기준으로 설명되어있지만, 여러대의 머신에서도 설정파일만 적용해주면 동일하게 실행할 수 있다.
위의 실행방법을 하나씩 따라해보면 실제로는 실행하기 어렵지 않을 것으로 보인다. 이상으로 Storm-ESPER의 실행기를 마친다.
'Real-time Big Data' 카테고리의 다른 글
| Twitter sample public status rolling top count project for Apache storm starter (0) | 2015.07.21 |
|---|---|
| eBay Pulsar의 Jetstream 따라하기 (0) | 2015.06.23 |
| Storm-ESPER vs eBay Pulsar : 비용, 안정성, 확장성에 대한 비교 (0) | 2015.06.17 |
| eBay Pulsar 분석 - Pulsar Demo 실행을 통한 이해 (0) | 2015.06.10 |
| Pulsar - 실시간 분석 플랫폼 : White Paper (0) | 2015.05.27 |